

Wissenschaftliches Arbeiten mit Corpora am Textcorpus VGCoST vorgestellt
Der Begriff ‚linguistischer Corpus‘ fiel bereits einige Male hier auf dem Blog im Zusammenhang mit Videospielen. Vielleicht habt ihr ja bereits auf der Startseite davon gelesen oder sogar die eigens dafür eingerichtete Seite besucht. Jetzt möchte ich euch meinen Corpus an sich noch einmal im Detail vorstellen und euch daran einige Anwendungsmöglichkeiten von Corpora vorführen.

Der Video Game Corpus of Speech and Text, kurz VGCoST, ist in einem Satz schnell erklärt: Es handelt sich um eine Sammlung von so vielen möglichst vollständigen Dialog- und Textdateien aus Videospielen. Das ist im Grunde schon so ganz interessant, wenn man einen seiner Lieblingstitel darin findet oder einfach gerne durch Dialogdateien stöbert. Tatsächlich praktisch wird es aber, wenn ich euch verrate, dass die einzelnen Dateien so aufbereitet werden, dass sie möglichst repräsentativ für das eigentliche Spiel sind und damit super für die Forschung: Rauschen in Form von Systemnachrichten oder Programmiercode wird gefiltert (beinahe ausnahmslos manuell) und Dialoge werden in eine lesbare Form gebracht (ähnlich einem Theaterskript). Metadaten wie Veröffentlichungsdatum und Entwickler gehören ebenfalls in eine solche Datei, um sie möglichst benutzerfreundlich zu machen.
Aber warum das alles eigentlich?
Ein solcher Corpus ist in erster Linie eine Forschungsgrundlage, kein richtiges Werkzeug. Damit ihm Wert zukommt, muss er benutzt werden, und damit er benutzbar ist, muss er mit den Werkzeugen funktionieren, die einem Forscher zu Verfügung stehen. Solche Werkzeuge reichen von der simplen Suchfunktion des Texteditors bis hin zu genau auf die Bedürfnisse des entsprechenden Benutzers zugeschnittenen Sortierprogrammen. Solche Corpustools werden oft von Universitäten speziell für eine bestimmte Art Corpus entwickelt, viele funktionieren aber auch ubiquitär. Egal für welchen speziellen Fall die Tools zugeschnitten sind: Die Grundfunktionen sind oft die gleichen. Einzelne Worte oder ganze Phrasen können gesucht, gezählt und mit ihren Nachbarn im Satz verglichen werden; oft lassen sich auch diverse Textdateien gegeneinander vergleichen. Ein solches Werkzeug, das jedem frei zugänglich ist, ist beispielsweise AntConc; und genau daran möchte ich euch kurz zeigen, was sich potenziell mit meinem VGCoST alles anstellen lässt.
Nehmen wir an, ich möchte folgende Spiele genauer untersuchen: Portal und Portal 2. Die gesammelten Dialoge beider Spiele sind im VGCoST vorhanden, ich kann also die entsprechenden Textdateien mit AntConc öffnen. Nun kann ich nach diversen Dingen suchen. Ratet doch mal: Wie oft singt GLaDOS „Still Alive“ im gleichnamigen Creditsong von Portal?

Konkordanz von „Still Alive“ im Video Game Corpus of Text and Speech
11 Mal also. Wenn ich möchte, kann ich mir die einzelnen Textzeilen auch ansehen, sodass ich weiß, aus welcher Strophe sie stammen:
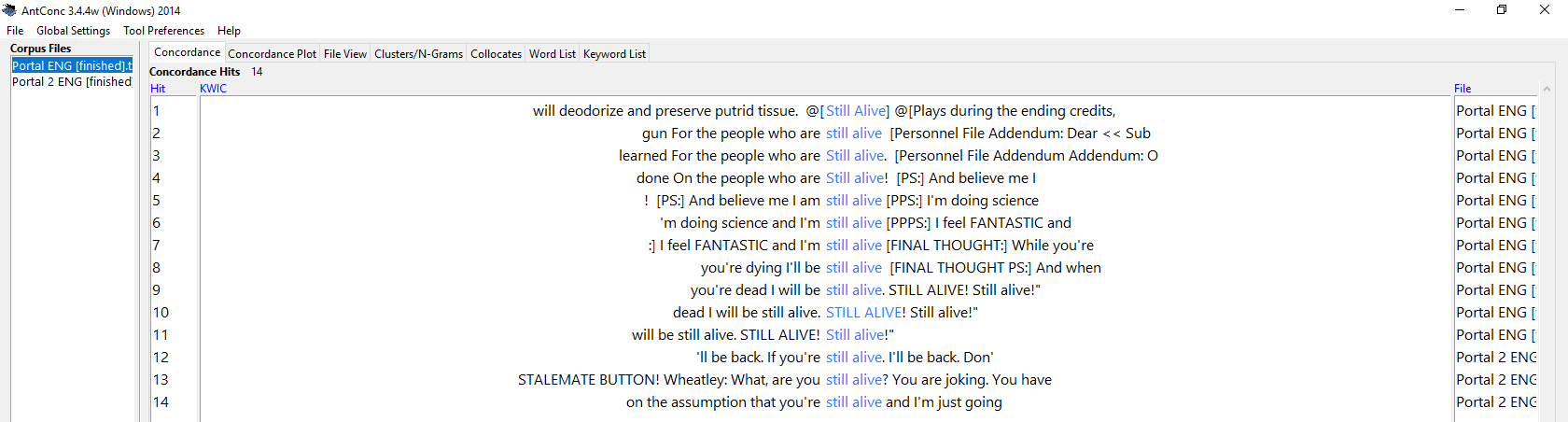
Konkordanz von „Still Alive“ im Video Game Corpus of Text and Speech: Einzelne Zeilen.
Da wird mitsingen gleich viel leichter.
Und angenommen, ich möchte wissen, welche Worte GLaDOS verwendet, wenn sie darüber spricht, Chell mit Nervengift zu töten. Dann kann ich nach sogenannten Clustern suchen, also nach festen, mehrfach auftauchenden Wortgruppen:

Cluster von „neurotoxin“ im Video Game Corpus of Text and Speech
Kein Wunder, dass ‚deadly neurotoxin‘ ganz oben mit dabei ist. Das Tool zeigt mir dabei direkt auch an, in wie vielen der ausgewählten Dateien (also in wie vielen Spielen) die Wortkombination so vorkommt.
Auch Worte zählen ist kein Problem. Oft lässt diese simple Methode die stärksten Rückschlüsse zu; ist es nicht interessant, dass der Name ‚Wheatley‘ fast genau so oft wie ‚GLaDOS‘ erwähnt wird, obwohl GLaDOS in beiden Spielen vorkommt, Wheatley aber nur im zweiten Teil?

Wortfrequenz von „GLaDOS“ und „Wheatley“ im Video Game Corpus of Text and Speech
So gewonnene Infos können quantitative Fragen über Videospieltexte und -dialoge beantworten (etwa: „Wie oft wird GLaDOS erwähnt?“), aber auch Rückschlüsse für qualitative Analysen zulassen („Warum wird GLaDOS so oft erwähnt?“) Auf diese Art kann ein Corpus auch ein wertvolles Werkzeug für Literatur- und Medienwissenschaftler werden, und sogar Psychologen könnten durch einen entsprechenden Corpus Hinweise auf die Gedanken hinter den Aussagen bestimmter Charaktere finden.
Der Video Game Corpus of Text and Speech ist meines Wissens nach der erste, der eine solche Quellensammlung für Videospiele versucht – zumindest öffentlich frei verfügbar. Oft stellen sich Forscher oder Studenten für ihr entsprechendes Projekt einen Corpus zusammen, der nach Abschluss der Arbeit in der Vergessenheit verschwindet. VGCoST soll genau das nicht sein, sondern eine dauerhaft verfügbare Quelle für alle, die dem Thema genug abgewinnen können, um daran zu forschen. Ich plane, den Corpus stetig mit weiteren Spielen zu erweitern. Da ich allein an dem Projekt arbeite, wird das jedoch kein schneller Prozess. Hier könnt ihr euch einschalten, wenn ihr Lust habt: Wenn ihr Dialogdateien aus Spielen habt, die ihr vielleicht sogar selbst entwickelt habt, dann schickt sie mir gerne! Das manuelle Extrahieren von Dialogen aus Spielen ist langatmig und aufwendig, ich bin also über jedes bisschen Hilfe dankbar. Die Hauptversion des VGCoST ist englisch, deutsche Texte sammle ich derzeit jedoch auch, um sie aufzubereiten, wenn ich die Zeit dafür finde. Das erste große Update ist bereits in Arbeit; darin werdet ihr unter anderem Harry Potter und die Kammer des Schreckens für die PlayStation 2 und Gods Will Be Watching von Deconstructeam und Devolver Digital finden. Die Downloadseite wird ständig auf dem neuesten Stand gehalten und im herunterladbaren Ordner findet sich immer eine aktuelle Inhaltsübersicht sammt -verzeichnis.
Wenn ihr bis hierhin gelesen habt, vielen Dank für euer Interesse am Forschungsgegenstand Videospiel! Je mehr ihr darüber lest, nachdenkt und redet, desto mehr Fuß können wir unter den anderen zahlreichen Medienwissenschaften fassen. Still Alive!
The end.








Eine Antwort
[…] Vorgestellt: Eine wachsende Sammlung von Dialogen und Texten in Games (languageatplay.wordpress.com, Pascal Wagner) […]